
Trabajar con grabaciones exportadas en AWS S3 bucket
Una vez configurada la integración de acciones masivas de grabación de AWS S3 , puede exportar las grabaciones que se encuentran en Genesys Cloud de forma masiva a su bucket de AWS S3. Esta exportación puede realizarse automáticamente a través de una política de QM, o explícitamente invocando la API de acción masiva de grabación.
En este artículo se detalla el contenido que se exporta a su bucket de AWS S3.
Contenido del bucket AWS S3
Los archivos de grabación se exportan al bucket de AWS S3 en carpetas con la siguiente estructura:
s3://{bucket}/{organizationId}/year={year}/{month={mes}/day={día}/hour={hourOfDay}/conversation_id={conversationId}/
| Marcador de posición | Descripción |
|---|---|
| {cubo} | El nombre del bucket S3. |
| {idOrganización} | La identificación de la organización. |
| {year} | El año en que comenzó la conversación. |
| {mes} | El mes en el que comenzó la conversación (en dígitos). |
| {día} | El día en que comenzó la conversación. |
| {hourOfDay} |
La hora en la que comenzó la conversación. |
| {conversationId} |
La identificación de la conversación. |
La carpeta contiene todos los archivos de grabación que se conservan durante la conversación. Cada archivo de grabación tiene una grabación, y el nombre del archivo es el ID de grabación.
Cada archivo de grabación tiene su correspondiente archivo de metadatos JSON. El nombre del archivo de metadatos JSON lleva el sufijo "_metadata.json".
Los metadatos pueden utilizarse para buscar la grabación exportada. Para más información, consulte el ejemplo Athena+Glue (un ejemplo de servicio de búsqueda de grabaciones).
El archivo de metadatos está en formato JSON con el siguiente esquema.
{
“$schema”: “http://json-schema.org/draft-04/schema#”,
"tipo": "objeto",
"propiedades": {
"mediaType": {
"descripción": "Tipo de medio (uno de Llamada, Chat, Correo electrónico, Mensaje, Pantalla)",
"tipo": "cadena"
},
"mediaSubtype": {
"descripción": "El subtipo de la grabación (uno de Troncal, Estación, Consultar, Pantalla)",
"tipo": "cadena"
},
"mediaSubject": {
"descripción": "El tema de la grabación",
"tipo": "cadena"
},
"proveedor": {
"descripción": "Tipo de proveedor para la grabación, por ejemplo borde",
"tipo": "cadena"
},
“userIds”: {
"descripción": "Lista de usuarios",
"tipo": "array",
"items": [
{
"tipo": "cadena"
}
]
},
“startTime”: {
"descripción": "Hora de inicio de las grabaciones",
"tipo": "cadena"
},
"endTime": {
"descripción": "Hora de finalización de las grabaciones",
"tipo": "cadena"
},
"durationMs": {
"descripción": "Duración de la grabación",
"tipo": "entero"
},
"initialDirection": {
"descripción": "Dirección inicial de la conversación (entrada/salida)",
"tipo": "cadena"
},
"aniNormalizado": {
"descripción": "ANI",
"tipo": "cadena"
},
"aniDisplayable": {
"descripción": "ANI en forma visualizable",
"tipo": "cadena"
},
"dnisNormalized": {
"descripción": "DNIS",
"tipo": "cadena"
},
"dnisDisplayable": {
"descripción": "DNIS en forma visualizable",
"tipo": "cadena"
},
"queueIds": {
"descripción": "Lista de identificadores de cola para la grabación",
"tipo": "array",
"items": [
{
"tipo": "cadena"
}
]
},
"wrapupCodes": {
"descripción": "Códigos de recapitulación de la conversación",
"tipo": "array",
"items": [
{
"tipo": "cadena"
}
]
},
"organizationId": {
"descripción": "ID único para la conversación",
"tipo": "cadena"
},
"conversationId": {
"descripción": "ID único asociado a la conversación",
"tipo": "cadena"
},
“conversationStartTime”: {
"descripción": "Hora de inicio de la conversación",
"tipo": "cadena"
},
"conversationEndTime": {
"descripción": "La hora final de la conversación",
"tipo": "cadena"
},
"recordingId": {
"descripción": "ID único para la grabación",
"tipo": "cadena"
},
"filePath": {
"descripción": "Ruta original de la grabación",
"tipo": "cadena"
},
"fileSize": {
"descripción": "Tamaño del archivo de grabación",
"tipo": "entero"
},
"messageType": {
"descripción": "Tipo de plataforma de mensajes desde la que se originó el mensaje, por ejemplo, sms, twitter, line, facebook, whatsapp, webmessaging, open, instagram",
"tipo": "cadena"
},
“languageIds”: {
"descripción": "Identificador de la lengua",
"tipo": "array",
"items": [
{
"tipo": "cadena"
}
]
},
"screenInformation": {
"descripción": "Información específica de la pantalla, incluye el ID de la pantalla, posición X e Y, información de resolución",
"tipo": "objeto"
}
},
"requerido": [
"mediaType",
"proveedor",
“startTime”,
"endTime",
"duraciónMs",
"organizationId",
"conversationId",
“conversationStartTime”,
"conversationEndTime",
"recordingId",
“filePath”,
“fileSize”
]
}
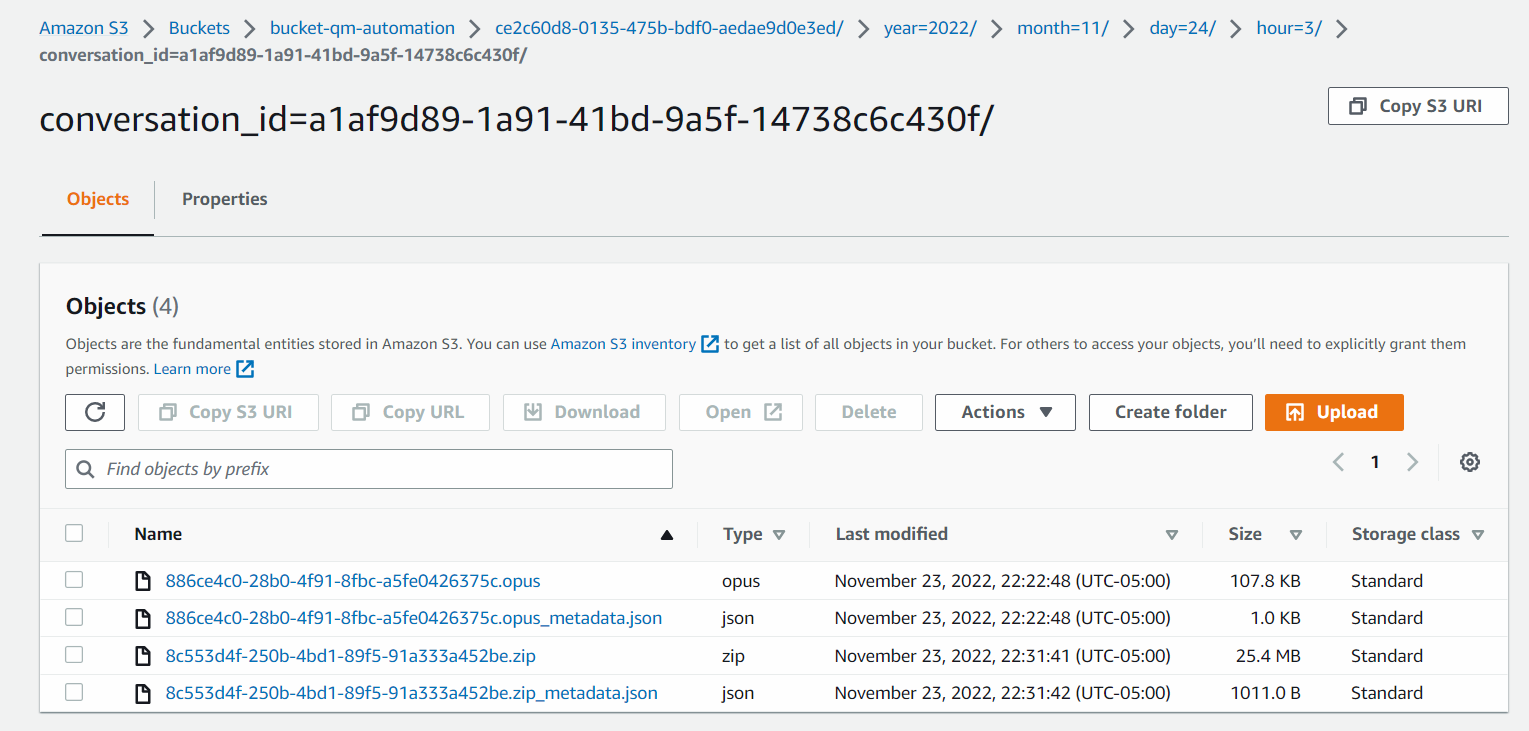
Por ejemplo, una conversación telefónica con la grabación de pantalla activada puede tener el siguiente contenido de carpeta.
En la imagen siguiente, el archivo .opus es el archivo de grabación de audio, el archivo .zip contiene el archivo de grabación de pantalla y los archivos .json son los metadatos JSON asociados a los respectivos archivos multimedia.
Haga clic en la imagen para ampliarla.
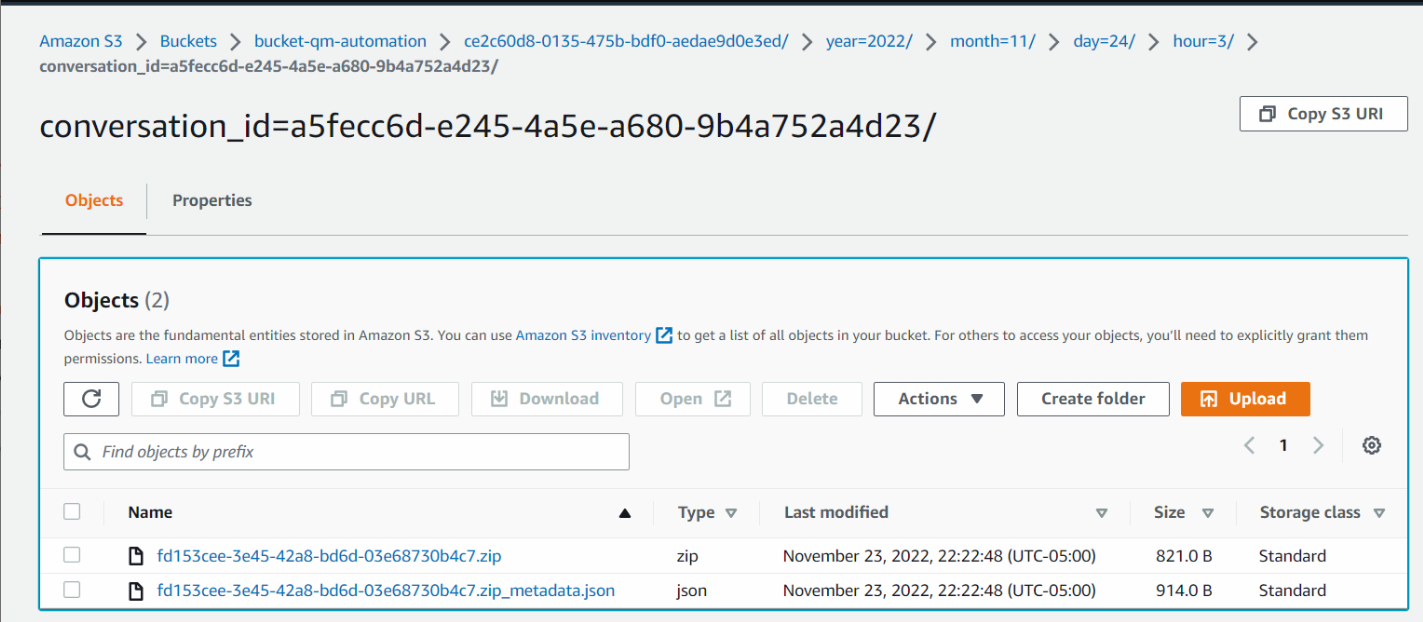
Una conversación digital puede tener el siguiente contenido de carpeta.
En la imagen siguiente, el archivo .zip contiene el archivo de grabación digital, y el archivo .json es el archivo JSON correspondiente.
Haga clic en la imagen para ampliarla.
Cifrado
Su bucket de S3 ya está configurado con AWS S3 Server-Side Encryption (SSE). Puede haber sido habilitado con claves de cifrado administradas por Amazon S3 (SSE-S3), o habilitado con las claves administradas por AWS, o claves proporcionadas por el cliente desde el servicio de administración de claves de AWS (SSE-KMS).
AWS S3 Server-Side Encryption (SSE) protege los archivos de grabación en reposo en el bucket de S3. Cuando los archivos se recuperan del bucket, AWS descifra automáticamente el contenido del archivo.
Si su sistema incluye una opción adicional Recording Export Encryption, deberá descifrar el contenido del archivo usted mismo después de recuperar los archivos del bucket de S3.